I recently made some minor contributions to an open source project that took a GraphQL schema as its input and generated viable SQL dialects for various databases. Since I have worked with GraphQL quite a bit in the past I liked the idea of fleshing out a GraphQL API, which includes type definitions, and generating TypeScript functions that invoked SQL to perform underlying CRUD operations. Not dissimilar to how an ORM maps Java classes to SQL statements, or how Swagger-based code generators provide a framework generated from an REST API definition.
GraphQL has a simple yet extensible way of defining data types in a declarative way. These data types are used to define and validate the structure of HTTP POST calls to a server, where the POST body is JSON. There is also support for directives which allows tweaks can be made to the schema to inform a language generator (or validation engine) how to map GraphQL types to other language types. The drawback is that directives bind the GraphQL schema to a particular language or data store.
Deja vu all over again
Any sufficiently complex computer application has dealt with converting from one set of types defined in one language to a similar set of types in another. Off the top of my head:
- Object-Relational Mapping (ORM)
- UML CASE code generation
- Swagger
- XML Schema/Java PODO binding
- Semantic Object Model
- Castor
- Spring Roo
Defining data types and generating language-to-language mappings are a core part of these technologies, so this type of problem repeatedly crops up. It made me wonder if the general concept can be abstracted away from specific implementation details. What follows is a general outline of what such an abstraction might look like, and how it would operate.
Primitive and compound data types
A type is a named data structure definition. Data of a type must conform to the definition. I’m using the word “structure” in this case to refer to primitive data types and compound data types.
Primitive Data Types
These correspond to data stored atomically in memory. Most languages support the following:
- Integer
- Decimal
- Float
- Character
- Boolean
Some might include Currency and Date.
Compound Data Types
A compound type is defined as a container for primitive and other compound types. They go by various names:
- struct (C++)
- array
- complex type (XML Schema)
- Plain Old Data Object (PODO, various languages)
The programmer defines them, gives the definition a name, and uses instances of them in code. Unlike primitives, which are defined by the language, compound types are “custom” types.
Aspects of Universal Type System
A UTS schema, which defines primitive and compound types, does not dictate an implementation. In that sense, it is a purely conceptual and nonspecific description of types used in a domain. So an integer in UTS is whole number without constraint; likewise, a string is a contiguous set of characters without a fixed length. So, a UTS schema sketches out the kinds of data used in a domain, but it is not sufficient for an implementation on its own.
GraphQL has simplified cardinality constraints, and I think UTS would also. Those constraints can be tightened in the chosen target language(s) of the implementation.
So what good is it?
- as a conceptual model, it doesn’t get bogged down into implementation detail and therefore focuses on what is important to the domain expert, e.g. the business
- as a set of type definitions, it can be represented in other languages, which may introduce constraints of their own. Additional constraints can be defined by the developer via configuration.
Basic Components
From here on I will use the term “dialect” instead of “language”, as well as “subdialect” to mean a variation of a language. There is plenty of fuzziness in the ideas described below, as this article is intended as a thought piece and not as a detailed implementation guideline with all issues worked out in (or even accounted for).
The base definition
This is the core of UTS: a schema defining named types using primitives and composites. It might bear similarity to a GraphQL typedef schema. Since it defines a graph of relations between types, it is not unlike a relational database schema where table and columns follow a Table-per-Type structure.
Type inheritance is not directly supported, because UTS is not conceived as a way to classify types in terms of is-a relationships. UTS might support type extension as a convenient shorthand to reduce redundancy in definitions, but extension would not imply is-a classification, though a dialect implementation could interpret it as such.
Domain extensions
A means of extending the UTS language would allow for things like the definitions of additional primitive types, or value ranges for types defined in the base definition. It may also define cardinality constraints between a type and it’s child types. These are not language-specific constraints (though they incidentally could be), but constraints determined by the domain.
Dialect Configurations
These determine the default implementations for data representation in a dialect, such as TypeScript or SQL. In addition, subdialect extensions would allow for refinement of dialects. For instance, a SQL dialect extension would have subdialects, each specific a particular RDBMS.
Essentially, each language would share a common set of types, but implement them according to the language constraints. Let’s start with a basic diagram and build upon it further on.
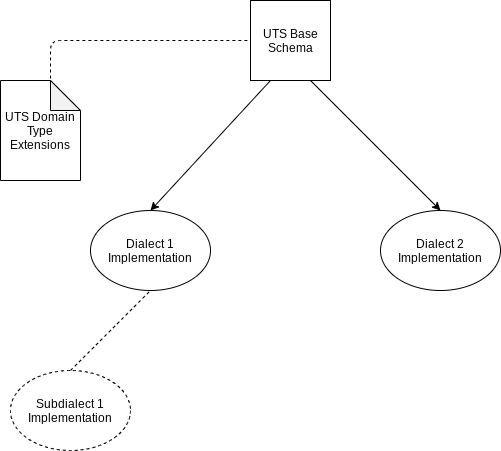
UTS base schema “sketches out” the types used in an application. It is useful to the data modeler modeling a business domain for the first time. There are several key elements yet to be discussed: dialect defaults, dialect-to-dialect bindings, and custom configurations.
Dialect Defaults
In order to generate types for a dialect, we have to know how to map a UTS type to dialect types. For the majority of cases, reasonable default types can be determined for any dialect. That’s not going to be sufficient in all cases, so there needs to be a way to override those default type mappings.
Dialect-to-Dialect Bindings
So it’s one thing to map UTS type definitions to actual language types, but in many scenarios one would want to cross language boundaries, say from JavaScript JSON “types” to SQL data definitions.
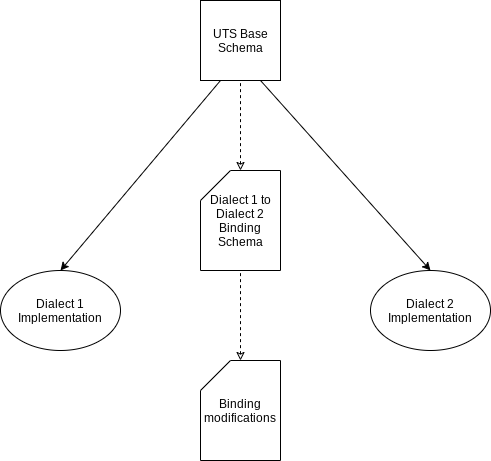
A default Binding Schema would be generated (or interpreted) by a UTS-compatible framework. The bindings can be modified by another set of definitions as determined by the data modeler. The binding document in turn can be used to generate mappings between types in Dialects 1 & 2.
There is considerable detail and complexity that would have to be worked out concerning data-mapping implementation between arbitrary dialects, but each mapping would in concept be similar to Object-Relational-Mapping or JavaScript object mapping to/from REST API POST content and result definitions.
Custom Configurations
Like the UTS-to-Language mappings, bindings would have to allow for customization via configuration files. Those configuration files would modify the default bindings (as predefined by UTS for various languages). The configuration might change type-to-type bindings at various scopes: by language, by module, by type, language subdialect (say a DBMS SQL variant), or other scopes TBD.
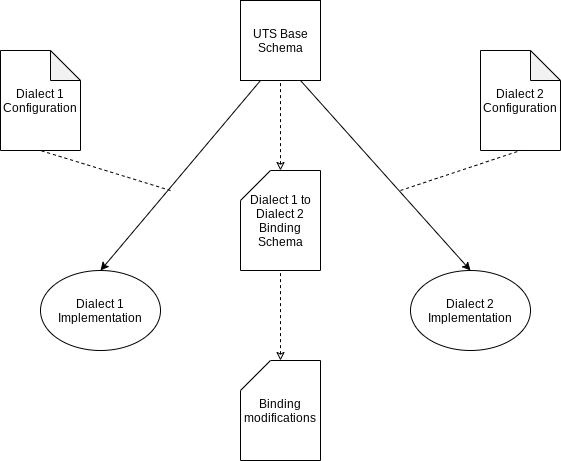
A universal type system really only makes sense if the default type-to-type mappings fall within the 80/20 rule: 80% of the defaults mappings are reasonable, and 20% need modification. For primitive types, this would often be the case for a specific language; however, in a language-to-language binding, range out-of-bounds conditions could occur.
An example outline of operation
From a UTS schema, both a SQL schema and TypeScript PODO definitions are created. Both are fully conformant to the UTS base definition (plus any domain extensions). The TypeScript and database are to talk to each other, so that the TypeScript PODOs have mechanism to pull and push data from the SQL database. The TypeScript PODOs and SQL Tables (table-by-type) are said to be bound.
Benefits
UTS would offer:
- rapid prototyping across different dialect implementations, useful for proof-of-concept demonstrations or for informing a base implementation.
- deliver an abstract schema that encapsulates domain concepts without bogging down in overly precise implementation details
- reasonable cross-language type-to-type default mappings
Editors could be adopted to UTS to provide linkage to (and maintenance of) dialects, sub-dialects, and their configuration values.
Further details
It would make sense to look at existing type definition languages and see if they could be adopted. I mentioned GraphQL, but other schema languages are viable base candidates. A key concept it to avoid tight binding of schema to implementation (as happens with GraphQL directives and Java annotations), and instead keep those separate concerns in separate definition files, apart from the schema itself.
A UTS engine might generate code or interpret schemas at runtime, or both. Information from a UTS schema can be used to enforce constraints that can’t be easily handled by generated code, such as associative data constraints.
Problems? There are always problems.
The biggest issue with code generation has traditionally be performance and maintenance. UTS would not offer a solution in that regard. It’s purpose it to get from concept to functional prototype in a rapidly, but at the same time provide a framework implementation that can be customized for performance and chosen technology platform. Reverse-engineering, versioning, and data migration issues are difficult problems that don’t lend themselves to easy solutions, but they are solvable. Whether the complexity of the solutions lend themselves to a UTS-based framework would remain to be seen.